Skills: An enhancement to Agentic RAG
Retrievable skills as an enhancement to your RAG pipeline.
The “R” in RAG is Expensive
Retrieval-Augmented Generation (RAG) is transformative, but it comes with a “tax”: network latency, token costs, and retrieval noise. In my work building an agentic code-generation pipeline for a domain-specific language (DSL), I saw this first-hand.
Our system orchestrates multiple sub-agents to generate code from documentation. We achieved a 100% compilation rate using a self-correction loop. However, our logs showed the agent repeatedly retrieving foundational concepts - data types, function signatures, and semantics — regardless of the query. Sending a vector search for a core language rule works, but it’s wasteful.
Enter Skills: Inspired by Anthropic’s SKILL.md pattern
To fix this, we implemented a skill registry inspired by Anthropic’s SKILL.md pattern. A skill is a pre-authored, version-controlled markdown file that the agent loads on demand.
How it Works:
- Cataloging: At startup, we inject a tiny catalog of available skills (names and “when to use” descriptions) into the system prompt.
- Progressive Disclosure: The agent only calls a
load_skill(name)tool when it needs the full body. This keeps the base prompt lean. - Redundancy Guards: If an agent tries to search for something already covered by a loaded skill, we short-circuit the search and redirect it to the local context.
Skills vs RAG: not a replacement, a layer
Skills do not replace retrieval. They sit in front of it:
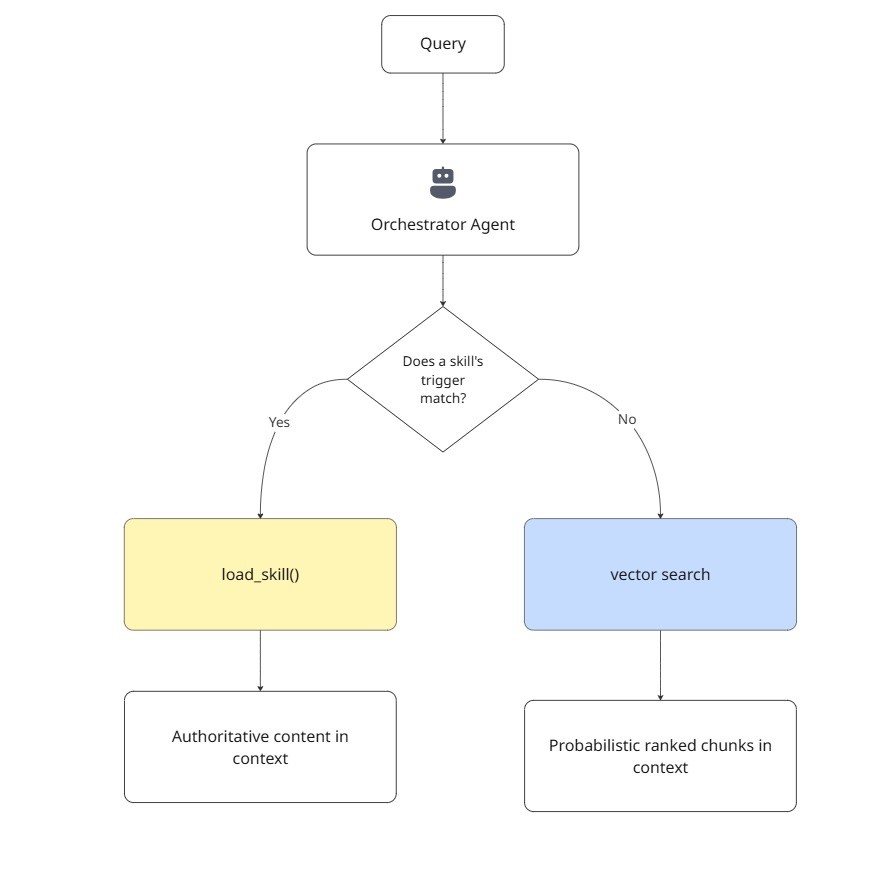
The decision tree is simple:
- Known concept, stable content, frequently asked → make it a skill.
- Novel question, long-tail, changes often → let RAG handle it.
Over time, you can promote frequently-retrieved topics from RAG to skills as you observe query patterns. The vector index becomes a safety net for the unexpected, not the primary path for the predictable.
In our DSL pipeline, this layer was a game-changer. By shaving off vector search round-trips for core documentation, we significantly reduced end-to-end latency—especially in multi-agent orchestration where these costs compound.
Key Principles for Implementation
- Keep Skills Focused: One skill, one concept. Don’t bloat the context.
- Metadata is the Contract: Be precise with
when_to_usedescriptions so the agent knows exactly when to trigger a load. - Code, Not Database: Treat skills like code. Store them in Git, review them in PRs, and deploy them alongside your agent.
- Promote from RAG: Track your vector search logs. When a retrieval target becomes predictable and stable, “promote” it to a skill.
Conclusion
Skills are to agentic RAG what a cache is to a database. By giving your agent a faster path for the answers it already knows, you save tokens, drop latency, and ensure the vector index remains a safety net for the unexpected—not a primary path for the predictable. .
- Code, Not Database: Treat skills like code. Store them in Git, review them in PRs, and deploy them alongside your agent.
- Promote from RAG: Track your vector search logs. When a retrieval target becomes predictable and stable, “promote” it to a skill.